OpenAl采用智谱标准评测GPT-4.1系列大模型快讯
TechWeb.com.cn
2025-04-15 21:03
导读
ComplexFuncBench是由智谱团队提出的专用于评估大模型复杂函数调用能力的测试基准,ComplexFuncBench要求大模型对真实场景下的用户需求进行细粒度理解,ComplexFuncBench主要评测大模型在128K的长上下文下进行多步带约束的函数调用的能力。
【TechWeb】4月15日消息,OpenAI发布的了最新GPT-4.1系列大模型,其中在评测函数调用能力时采用了ComplexFuncBench。
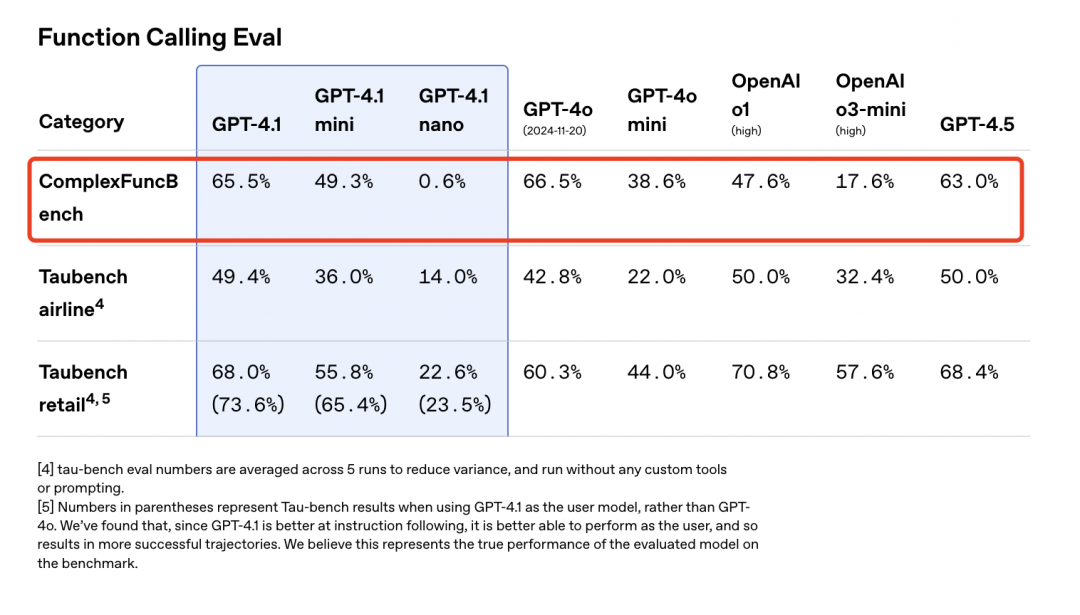
ComplexFuncBench是由智谱团队提出的专用于评估大模型复杂函数调用能力的测试基准。
据悉,ComplexFuncBench主要评测大模型在128K的长上下文下进行多步带约束的函数调用的能力。相比于现有函数调用测试基准,ComplexFuncBench要求大模型对真实场景下的用户需求进行细粒度理解,并在此基础上进行多步带推理的函数调用,这对模型的函数调用能力提出了更高的挑战。(果青)
模型
函数
调用
能力
ComplexFuncBench
1.TMT观察网遵循行业规范,任何转载的稿件都会明确标注作者和来源;
2.TMT观察网的原创文章,请转载时务必注明文章作者和"来源:TMT观察网",不尊重原创的行为TMT观察网或将追究责任;
3.作者投稿可能会经TMT观察网编辑修改或补充。
