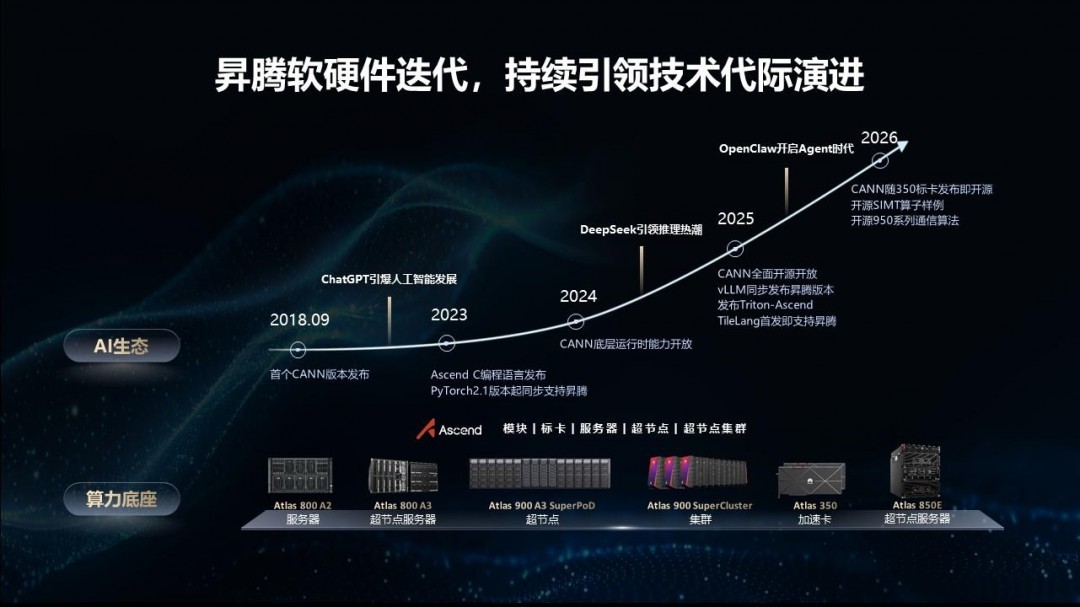
昇腾生态蝶变:CANN全面开源开放,以“好用易用”重塑AI底座快讯
CANN社区月活开发者达2000人,实现了昇腾超节点全系列产品对DeepSeek V4系列模型的支持,通过模型架构创新更好地支持了Agent和Coding场景。
【TechWeb】“时代洪水冲天下,长空激浪正当时。”在日前举办的昇腾生态媒体沟通会上,华为昇腾专家以此作结,系统性地向外界披露了昇腾在生态建设上的最新进展与核心战略。
CANN的底层重构
作为昇腾AI异构计算架构,CANN是连接硬件与上层应用的核心纽带,其性能与易用性直接决定昇腾生态的竞争力。
目前,行业可以仿照CUDA走一条“捷径”,但昇腾坚持从底层指令集、编译器到运行时全栈自研。
“我们把这一套原来像麻花团一样团在一起的软件,一块块结构化地拆开了。”华为昇腾专家在沟通会上坦言。自去年8月宣布CANN开源开放以来,昇腾团队在短短4个月内完成了原本规划一年半的软件架构重构工作。
如今,CANN已实现分层解耦与独立升级,主流API全面兼容。华为昇腾专家强调,如果做一套一模一样的仿制生态,虽然短期容易,但“一旦发生紧急情况,全套软件可能全废。”因此,昇腾坚持底层虚拟指令集、编译器自研,同时在上层尊重开发者习惯,全面兼容PyTorch、Triton等主流生态。
为了解决千万级Python开发者的痛点,昇腾今年正式推出了基于Python的开源算子编程体系PyPTO,与业界主流的Triton编程方式保持一致,实现了灵活性与便捷性的统一。华为昇腾专家用一个生动的比喻阐述了开发理念:“Python就是灵活方便,C语言就是性能,这两类必须都做好。我们要尊重开发者,他们更希望用Python,那就支持好Python。”
据透露,对于新发布的模型,从迁移到适配完成最短仅需6小时。就在沟通会举办后的第三天,即4月24日,DeepSeek V4-Pro和DeepSeek V4-Flash正式发布并开源,模型上下文处理长度由原有的128K显著扩展至1M,实现近10倍的容量提升,并首次增加了KV Cache滑窗和压缩算法,大幅减少Attention计算和访存开销,通过模型架构创新更好地支持了Agent和Coding场景。昇腾全程同步支持DeepSeek系列模型,通过双方芯模技术紧密协同,实现了昇腾超节点全系列产品对DeepSeek V4系列模型的支持。
从9张卡到4000张卡:让开发者“兵强马壮”
社区繁荣是生态成熟的标志。华为昇腾专家透露,昇腾开源社区已从初期的9张体验卡扩展到千卡级,今年更计划全年向社区提供4000张免费算力资源,其中过半为最新的昇腾950,开发者可以“零成本”进行开发、验证与落地。
硬件之外,还有“真金白银”的投入。除了现有的亿级激励,昇腾额外设立2000万元专项创新基金,面向个人开发者及普通贡献者,覆盖算子、框架、模型适配等领域的激励。“如果2000万花完了我再追加,2000个开发者每人发一万我也愿意。”华为昇腾专家表示。
人才汇聚的效应已经显现。目前,CANN社区月活开发者达2000人,累计算子开发者超过1.3万人,孵化了50多个开源项目,甚至吸引了中石油、南方电网等行业头部企业基于开源代码自主开发行业特性。
面对今年火爆的Agent趋势,昇腾迅速将AI能力反哺至自身的开发工具链。现场展示的昇腾Model Agent,由团队仅用一个月打造,覆盖了从模型检索、适配、量化、迁移到部署的全流程。“以前客户现场需要派专家驻守几天,现在用Agent工具,目标是一分钟找到模型,一小时验证昇腾运行,一天完成部署。”
写在最后
尽管成绩斐然,华为昇腾专家依然坦诚地剖析了不足。他强调,昇腾衡量生态健康度有两个核心维度:“我支持你,你也支持我”。昇腾正在通过全量特性支持率、主流模型算子支持率、CI/CD覆盖率等六大指标严格考核,要求对90多个主流开源社区的支持率维持在95%以上,力求实现从“能用”到“好用易用”的跨越。
从被动适配到主动融入,从封闭开发到全面开源,昇腾正在走一条艰难但坚实的自主生态之路。正如华为昇腾专家所说,在AI这个没有标准、瞬息万变的赛道上,唯一的护城河就是能否第一时间支持好开发者,能否让他们成功。当客户转了一圈回来说“还是你们最好”时,昇腾生态的蝶变或许才刚刚翻开序章。
1.TMT观察网遵循行业规范,任何转载的稿件都会明确标注作者和来源;
2.TMT观察网的原创文章,请转载时务必注明文章作者和"来源:TMT观察网",不尊重原创的行为TMT观察网或将追究责任;
3.作者投稿可能会经TMT观察网编辑修改或补充。
