百度千帆发布端到端文档智能模型Qianfan-OCR:4B参数,登顶OmniDocBench快讯
Qianfan-OCR在文档解析与理解一体化能力上的领先表现,该模型基于统一的视觉语言架构,通过统一的端到端视觉语言模型。
【TechWeb】3月19日消息,百度千帆正式发布全新端到端文档智能模型 Qianfan-OCR。该模型基于统一的视觉语言架构,以4B参数规模实现了对文档解析、版面分析、文字识别与语义理解的全面融合,在多项权威评测中取得领先表现。
目前,Qianfan-OCR已在千帆平台上线,并同步在HuggingFace开源了模型权重,面向开发者与企业用户开放使用。
据介绍,在核心Benchmark中,Qianfan-OCR表现尤为突出。在 OmniDocBench v1.5上取得 93.12分的成绩,端到端模型中位列第一;OCRBench远高于同尺寸通用视觉语言模型和专用OCR模型;在关键信息提取(KIE)的多个公开榜单总分上,超过了Google Gemini 3-Pro等商用模型。
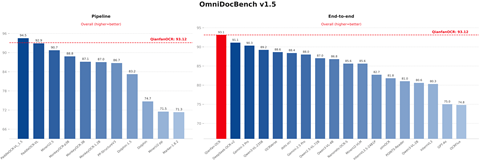
在图表理解等复杂任务中,端到端模型的优势更加明显,Qianfan-OCR在ChartQA、ChartBench等6项图表理解复杂任务中,拿下了5项最佳成绩,展现了强大的结构理解与多模态推理能力。
传统 OCR 系统普遍沿用“检测+识别+LLM”三段式Pipeline架构。这一模式虽已工程成熟,但多阶段串联处理会在各环节不断放大误差,且文本逐块提取过程中原有的空间结构与视觉上下文信息往往遭到破坏,使得图表、复杂表格等内容的理解能力受到明显制约。
Qianfan-OCR 从底层架构出发进行重构,通过统一的端到端视觉语言模型,直接从文档图像生成结构化结果,完整保留视觉信息,实现从“看见文档”到“理解文档”的一步直达,在结构理解与推理任务中具备更高的一致性与准确性。
Qianfan-OCR在文档解析与理解一体化能力上的领先表现,进一步验证了端到端技术路线的可行性与先进性,标志着文档智能能力正从“流程拼接”迈向“模型统一”的新阶段。(宜月)
1.TMT观察网遵循行业规范,任何转载的稿件都会明确标注作者和来源;
2.TMT观察网的原创文章,请转载时务必注明文章作者和"来源:TMT观察网",不尊重原创的行为TMT观察网或将追究责任;
3.作者投稿可能会经TMT观察网编辑修改或补充。
